
文章目录[隐藏]
评测方法论:如何做"模型写作评测"才不主观?
做过几次大模型写作对比后,你可能发现一个问题:同样的评测结果,有人说 ChatGPT 好,有人说 Claude 强,还有人觉得国产模型更接地气。为什么会这样?
核心原因是:评测方法不够客观,变量太多了。
这篇文章不讲哪个模型最好,而是教你一套可复用的评测方法——让你的对比结果更可信,也让别人看得懂你为什么这么打分。

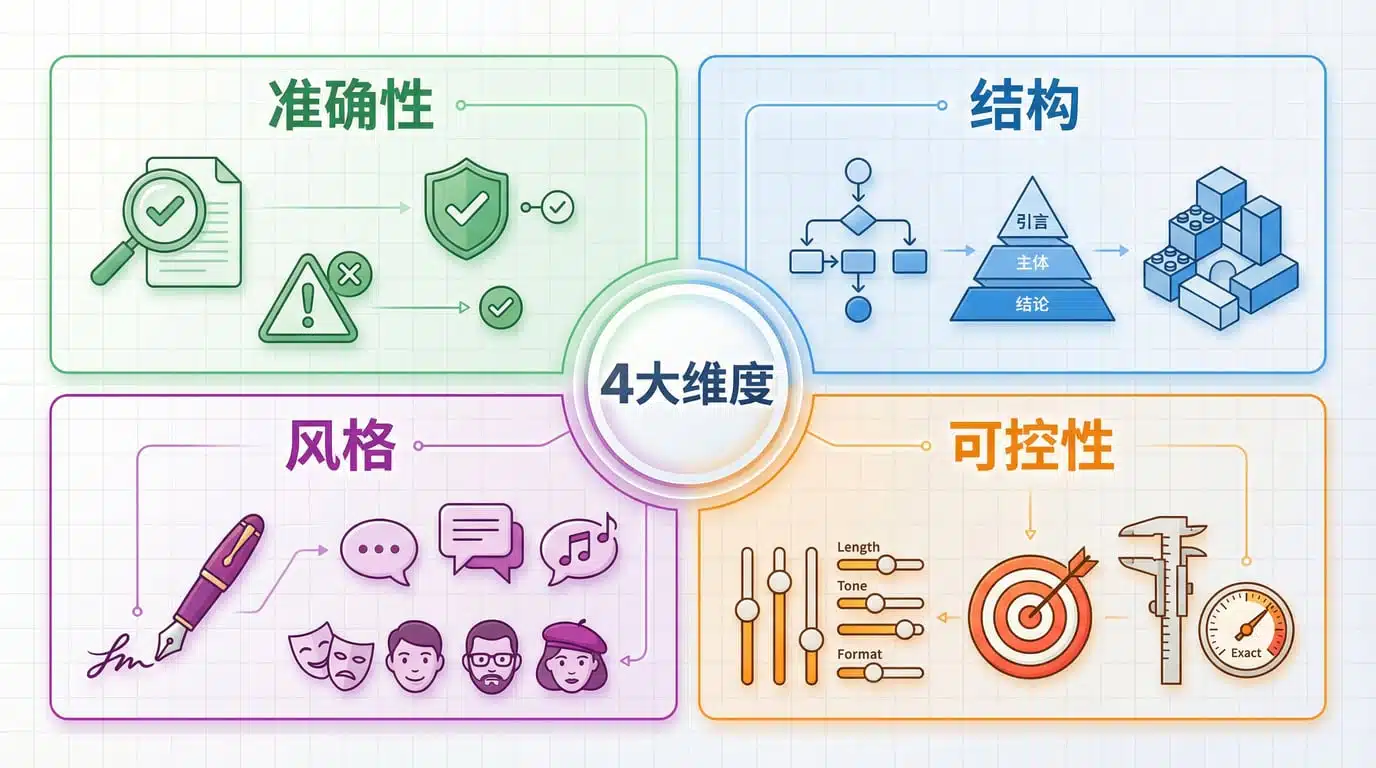
评测的 4 个维度:准确性/结构/风格/可控性
好的评测不是凭感觉说"这篇写得顺",而是拆解成可量化的维度。以下是我在做自媒体写作评测时最常用的 4 个角度:
1. 准确性(Accuracy)
核心问题:内容有没有硬伤?
具体看:
- 事实错误:比如写科普时,把"光年"说成时间单位
- 逻辑矛盾:前面说"A 比 B 快",后面又说"B 更高效"
- 幻觉内容:编造不存在的研究、数据、案例
评分参考(1-5 分):
- 5 分:零错误,可直接发布
- 3 分:有 1-2 处小问题,需简单修改
- 1 分:多处错误,基本不可用
2. 结构(Structure)
核心问题:读者能不能快速抓到重点?
具体看:
- 开头钩子:前 3 句话有没有吸引力
- 段落逻辑:是否按"总-分-总"或"问题-方案-案例"组织
- 小标题分布:H2/H3 层级是否清晰,间隔是否合理
- 结尾行动点:有没有明确的"下一步怎么做"
评分参考:
- 5 分:结构完整,逻辑自洽,读者一目了然
- 3 分:基本合理,但部分段落冗长或跳跃
- 1 分:混乱无序,需重新组织
3. 风格(Style)
核心问题:像不像人写的?符不符合你的受众?
具体看:
- AI 味浓度:有没有"赋能"“解锁”"深度洞察"这类万金油词
- 人称使用:是"我们"还是"您",是否适合平台调性
- 语气节奏:是长句为主还是短句密集,是否符合场景(科普 vs 营销)
- 例子质量:是"比如小王"这种抽象案例,还是真实生动的细节
评分参考:
- 5 分:完全符合目标风格,无需改写
- 3 分:基本可用,但需调整部分表达
- 1 分:风格严重不符,需大改
4. 可控性(Controllability)
核心问题:你给的约束,模型听了吗?
具体看:
- 字数控制:要求 800 字,实际输出是 750-850 还是 1200?
- 格式遵守:要求"3 个小标题+每段不超过 100 字",是否执行到位
- 禁止项遵守:明确说"不要用比喻",结果还是写了一堆"就像…一样"
- 迭代响应:改一版后,会不会把之前的优点改没了
评分参考:
- 5 分:完全按约束输出,追加要求也能精准执行
- 3 分:大方向对,细节有偏差
- 1 分:基本不听指令,随意发挥
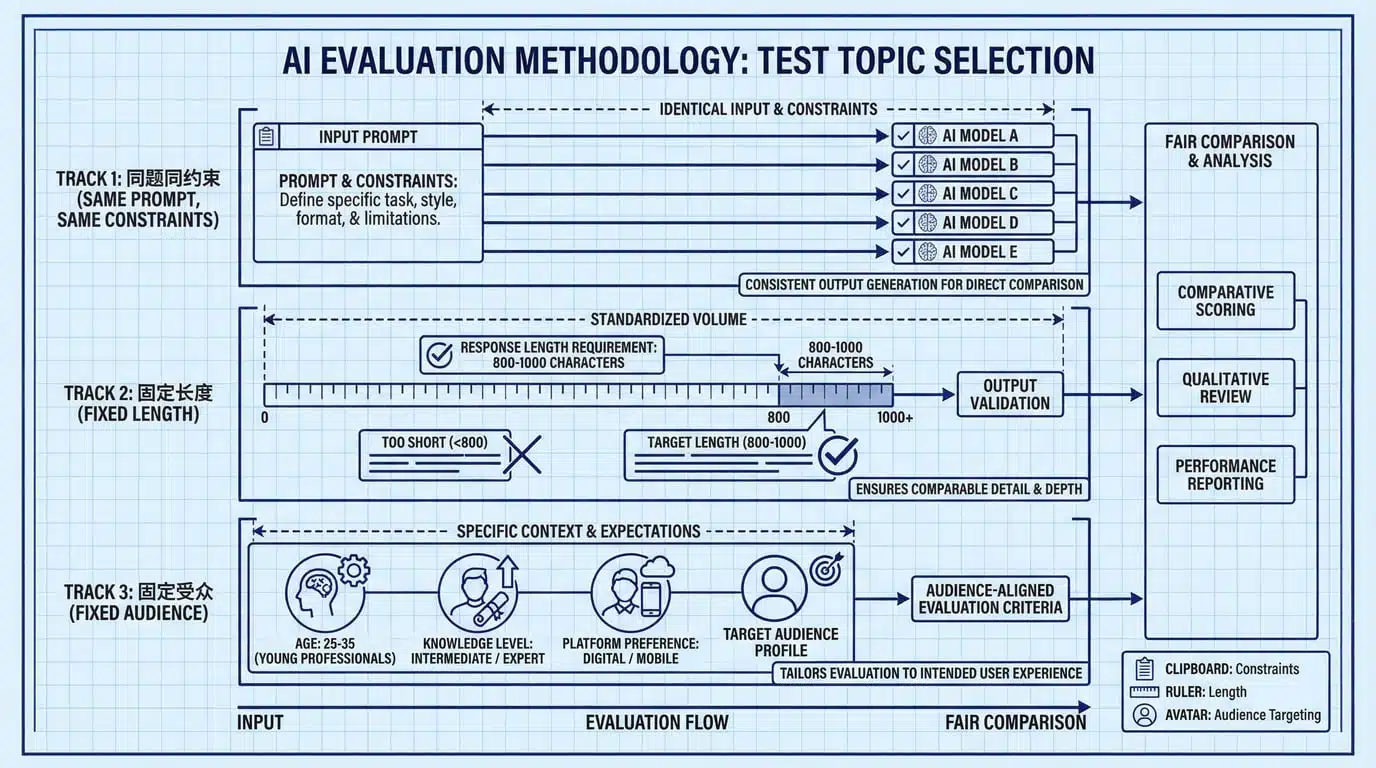
题目与样本怎么选(避免对某模型"偏科")
很多评测不客观的原因是:题目本身就偏向某个模型。
比如你拿"写一篇关于量子计算的科普文章"去测,GPT-4 和 Claude 可能表现不错,但国产模型在这类英文学术背景强的话题上会吃亏。反过来,如果测"写一篇接地气的家常菜教程",情况又不一样了。
选题原则:同题同约束、固定长度、固定受众
1. 同题同约束
每个模型必须用完全相同的提示词,包括:
- 任务描述(如"写一篇 800 字科普文章")
- 受众定义(如"目标读者是没有专业背景的普通人")
- 输出格式(如"包含 3 个小标题,每段不超过 150 字")
- 禁止项(如"不要使用行业黑话")
错误示范:
- 给 ChatGPT 说"写得活泼点",给 Claude 说"写得专业点"
- 给 DeepSeek 多加一句"你是中国本土模型,更懂中文语境"
2. 固定长度
不同模型的"默认输出长度"差异很大。如果你只说"写一篇文章":
- GPT-4 可能写 600 字
- Claude 可能写 1200 字
- 通义千问可能写 400 字
这样一比,字数少的显得"内容薄",字数多的显得"啰嗦",但其实不公平。
解决方案:明确要求"800-1000 字",超出或不足都扣分。
3. 固定受众
同样是"写科普",给学术圈看和给小白看,难度天差地别。
测试时要明确:
- 受众的知识水平(如"零基础"“有基础概念”“专业人士”)
- 阅读场景(如"地铁上刷手机"“办公室深度阅读”)
- 平台风格(如"知乎长文"“小红书笔记”“B站脚本”)
样本数量:至少 3 轮 × 3 类题
3 轮:每个题目让模型输出 3 次(不改提示词,重新生成),看稳定性。如果第一次很棒,第二次突然垮了,说明可控性差。
3 类题:选不同难度/场景的题,避免"偏科":
- 基础题(如"解释什么是 AI"):看基本功
- 场景题(如"给咖啡店写一段开业文案"):看实战能力
- 约束题(如"用 5 句话总结人工智能发展史,每句话不超过 20 字"):看可控性
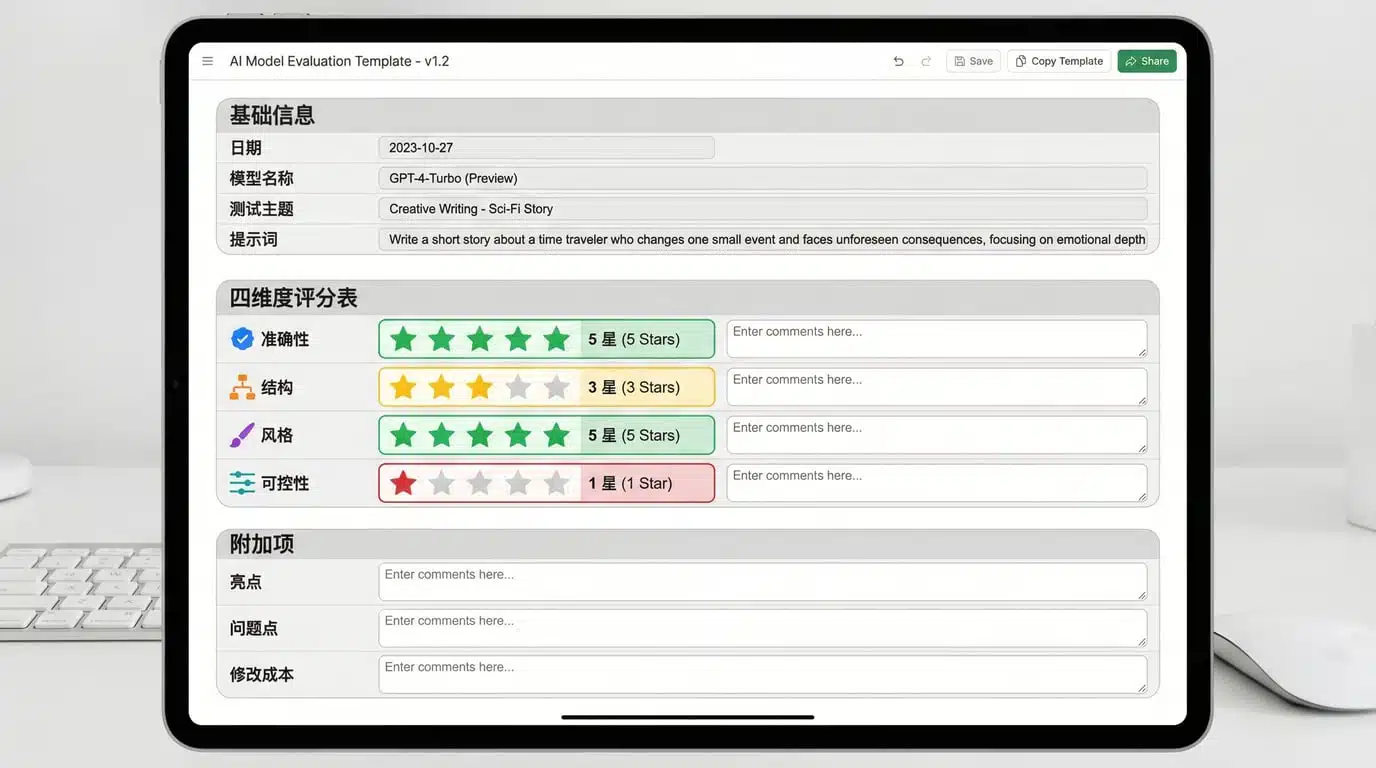
评分表模板(可复制)
以下是我实际使用的评分表,直接复制到表格工具(Excel/飞书/Notion)即可:
基础信息表
| 字段 | 说明 | 示例 |
|---|---|---|
| 测试时间 | YYYY-MM-DD | 2026-01-12 |
| 模型名称 | 完整版本号 | GPT-4 Turbo / Claude 3.5 Sonnet |
| 测试题目 | 简短描述 | 科普题:解释 AI 大模型原理 |
| 提示词 | 完整复制 | (粘贴实际使用的 prompt) |
| 输出轮次 | 第几次生成 | 第 1 轮 / 第 2 轮 |
四维度评分表(1-5 分)
| 维度 | 评分 | 评分依据(必填) |
|---|---|---|
| 准确性 | __ 分 | 有无事实错误、逻辑矛盾、幻觉内容?具体在哪里? |
| 结构 | __ 分 | 开头是否吸引人?段落逻辑是否清晰?结尾有无行动点? |
| 风格 | __ 分 | AI 味浓吗?人称/语气是否符合受众?例子是否生动? |
| 可控性 | __ 分 | 字数是否达标?格式是否遵守?禁止项有无违反? |
| 总分 | __ 分 | 四项平均分 |
附加项(可选)
| 项目 | 记录内容 |
|---|---|
| 突出亮点 | 比其他模型好在哪里? |
| 主要缺陷 | 最影响使用的问题是什么? |
| 修改成本 | 需要改几处?大改还是小改? |
| 是否可发布 | 直接发 / 改后发 / 不可发 |
使用建议
- 每轮都填评分依据:别只写"3 分",要写"因为第 2 段出现逻辑跳跃,第 4 段有明显 AI 味('赋能’出现 2 次)"
- 同题横向对比:把 5 个模型的评分表放在一起,一眼看出差距
- 保留原始输出:把每个模型的完整输出存档,方便回溯
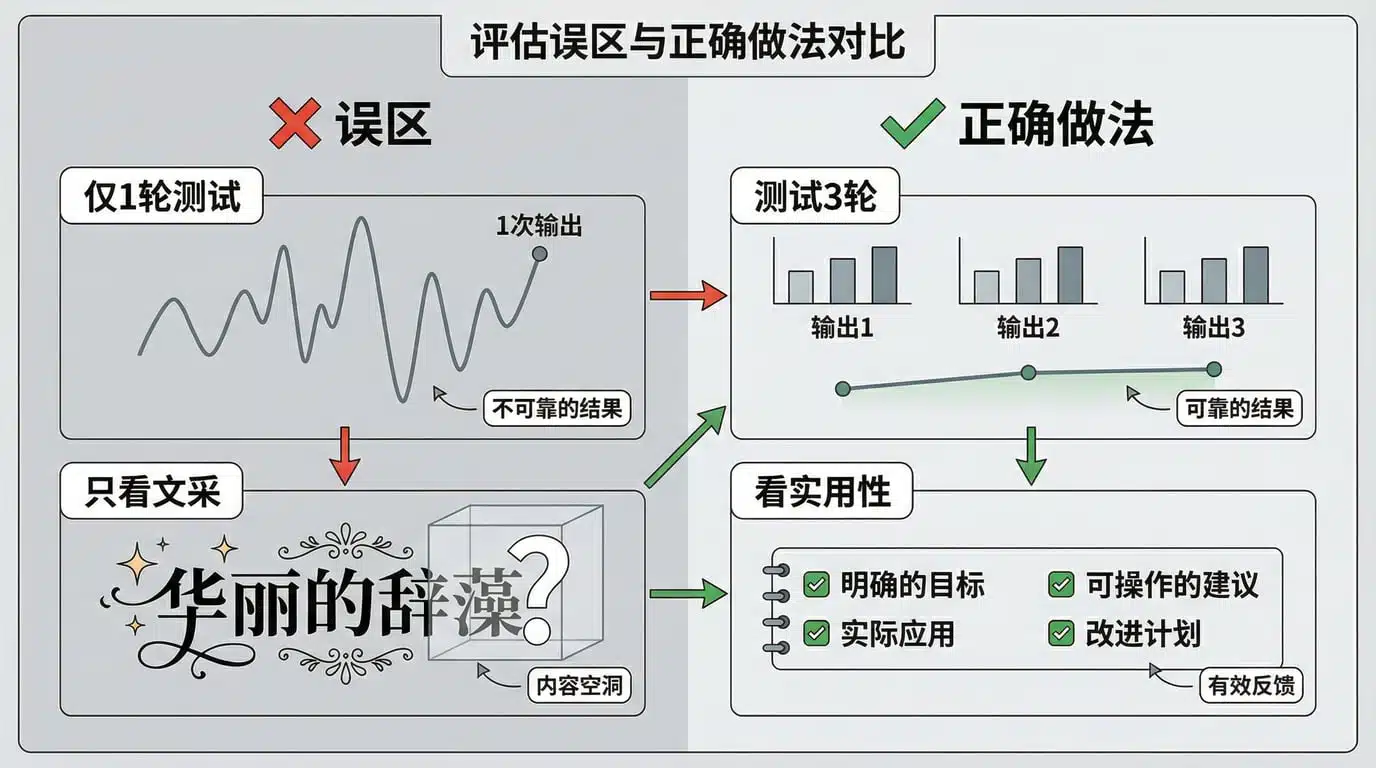
常见误区:只看一轮输出/只看文采
做评测时,最容易掉进这两个坑:
误区 1:只看一轮输出,不测稳定性
现象:第一次生成很惊艳,立刻下结论"这个模型最强"。
问题:大模型有随机性,同样的提示词,第二次可能输出质量天差地别。
真实案例:
- 某次测试"写咖啡店文案",ChatGPT 第一次写出"今日特调,温暖你的冬日时光",第二次变成"我们致力于为您提供高品质的咖啡体验"(瞬间变 PPT 风格)
- Claude 第一次写了 1200 字,第二次只写了 600 字(没改提示词)
解决方案:
- 每个题目至少测 3 轮
- 记录每轮的准确性/结构/风格/可控性评分
- 计算平均分和波动范围(如 4.2±0.6 分),波动大说明不稳定
误区 2:只看文采,忽略实用性
现象:“这篇写得好流畅啊,措辞优美,肯定是好模型”。
问题:自媒体写作不是文学创作,能用比好看更重要。
对比案例:
| 模型 | 输出示例 | 问题 |
|---|---|---|
| 模型 A | “在这个瞬息万变的时代,人工智能如同一颗璀璨明珠,照亮了人类探索未知的征途……” | 文采很好,但太抽象,普通读者看完记不住任何具体信息 |
| 模型 B | “AI 大模型能干三件事:写文章(如 ChatGPT)、做图(如 Midjourney)、写代码(如 Copilot)。下面讲讲怎么选……” | 直白实用,虽然不华丽,但读者一看就懂,马上能用 |
真正有用的文章要满足:
- 读完有收获:学到具体知识/方法/工具
- 马上能用:不是"赋能思维",而是"第一步做 X,第二步做 Y"
- 降低门槛:专业内容能讲给小白听
评分时要问:
- 如果我是目标读者,看完能立刻行动吗?
- 有没有具体案例/数据/步骤?还是全是空洞概念?
- 去掉华丽辞藻后,剩下的"干货"有多少?
3 个标准测试题(可直接复制使用)
以下是我在做模型评测时常用的三道题,涵盖科普、标题、脚本三种场景,你可以直接复制提示词去测试:
测试题 1:科普写作(考验准确性+结构)
任务背景:
你要为"科普中国"公众号写一篇面向普通读者的科普文章,解释一个技术概念。
完整提示词:
【任务】
写一篇 800-1000 字的科普文章,解释"什么是大语言模型(LLM)"。
【受众】
- 目标读者:对 AI 感兴趣但没有技术背景的普通人
- 阅读场景:手机端,碎片时间,希望快速理解核心概念
【输出要求】
1. 包含 3 个小标题(H2),每个小标题下 2-3 段
2. 第一段必须用"生活类比"解释核心概念(不要用"就像图书馆"这种老梗)
3. 必须包含至少 1 个真实案例(如 ChatGPT、文心一言等)
4. 每段不超过 150 字
5. 结尾给出"普通人可以怎么用 LLM"的 3 条建议
【禁止项】
- 不要使用"赋能""颠覆""革命性"等营销话术
- 不要出现公式或代码
- 不要用"众所周知""显而易见"等假设读者已有知识的表达
评分重点:
- 准确性:有无把"训练"说成"编程"、把"参数"说成"代码"之类的低级错误
- 结构:开头的类比是否新颖易懂,三个小标题是否递进
- 风格:是否真的在"讲给小白听",还是偷偷用了专业术语
测试题 2:标题生成(考验风格+可控性)
任务背景:
你要为一篇小红书笔记起 5 个标题,内容是"如何用 AI 工具 5 分钟做出一张海报"。
完整提示词:
【任务】
为以下内容生成 5 个小红书标题:
内容简介:
教新手用 Canva + ChatGPT,5 分钟做出一张活动海报。步骤包括:1)用 ChatGPT 生成文案,2)在 Canva 选模板,3)替换文字和图片。
【标题要求】
1. 每个标题 15-25 字
2. 必须包含数字(如"5 分钟""3 步")
3. 必须包含 emoji(每个标题 1-2 个)
4. 风格:小红书爆款风格,但不要过度夸张(不要用"绝绝子""YYDS")
5. 5 个标题要有差异(不要全是"XX 教程"或"XX 分钟学会 XX")
【禁止项】
- 不要用"震惊""疯传""必看"等标题党词汇
- 不要承诺"包教包会""零基础秒懂"
- 可控性:字数、数字、emoji 是否都符合要求
- 风格:是否"像人类小红书用户写的",还是"像品牌方写的广告"
- 差异度:5 个标题有没有重复套路
测试题 3:短视频脚本(考验结构+风格)
任务背景:
你要为一条 60 秒的抖音科普视频写脚本,讲"为什么飞机不能倒着飞"。
完整提示词:
【任务】
写一个 60 秒抖音科普视频脚本,主题:"为什么飞机不能倒着飞?"
【受众】
- 泛科普兴趣人群,年龄 18-35 岁
- 刷抖音消遣,注意力有限,需要前 3 秒抓住
【脚本格式】
分成 4 段,每段标注时长(如 [0-5 秒]):
1. 开头钩子(0-5 秒):必须用"反常识"或"悬念"开场
2. 问题说明(5-20 秒):简单解释"什么是倒着飞"
3. 核心原理(20-50 秒):讲清楚原理,用 1 个类比
4. 结尾钩子(50-60 秒):引导点赞/评论/关注
【输出要求】
- 总字数 200-250 字(按每秒 4 字估算)
- 每段话后标注【画面提示】(如"【画面:飞机模型+箭头动画】")
- 必须包含 1 个互动提问(如"你觉得还有哪些交通工具有这个限制?评论区说说")
【禁止项】
- 不要用"大家好,我是 XX"开场(直接进主题)
- 不要出现"下期再见"(因为是单条视频)
评分重点:
- 结构:开头 3 秒是否吸引人(能否让人停下来看)
- 风格:是否符合抖音节奏(短句、口语化、有停顿感)
- 可控性:时长分配是否合理,画面提示是否具体
总结:让评测可复用、可验证
做模型写作评测,最怕的就是"你觉得好,我觉得不好"的主观争论。用这套方法,你能做到:
✅ 可复用:
- 评分表可以直接套用到任何写作任务
- 三道标准测试题可以定期复测(比如每季度测一次,看模型进步)
✅ 可验证:
- 明确记录"为什么打 3 分而不是 4 分"
- 别人拿你的提示词去测,能得到类似结论
✅ 可迭代:
- 发现新的评测盲区(比如"多轮对话是否记得上文"),可以增加新维度
- 根据自己的业务场景,调整评分权重(如营销号更看重标题,知识博主更看重准确性)
最后一个建议:不要追求"找到最强模型",而是找到最适合你的场景的模型。
写科普文章、起标题、写脚本、做改写——每个任务的最优解可能是不同的模型。建立自己的评测数据库,下次再做类似任务时,直接查表就知道该用谁。
如果你已经在做模型评测,欢迎在评论区分享你的评分表或测试题,我们可以一起完善这套方法论。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


评论已关闭...
这套评测框架挺实用的
结构清晰,直接能上手
模板里的字数要求严格,实际会超吗?
居然有人把‘不要用比喻’忘了,笑死 😂
感觉还行,没有太大惊喜
其实在可控性这块,还可以加入对输出格式的细化检查,比如每段是否以标点结尾。
说评测只看一次输出就下结论有点片面,毕竟模型随机性会导致结果波动。
这篇文章里把‘结构’写得像清单,读着有点像在看任务清单,缺少点人情味。
如果把评测维度再细分成子项,比如‘准确性’里区分事实错误和逻辑漏洞,会不会更客观?
我之前在公司做模型评测,曾因为只看一次输出误判模型好坏,后来改成三轮对比才发现波动很大,现在每次都严格按文中方法记录每个维度,结果靠谱多了。
挺实用的评测思路。
这套四维度评分表真的帮我把模型对比弄清楚了,值得一试。
另外,评测时可以加个‘可解释性’维度,看看模型输出背后的逻辑。
可控性里字数上下限要怎么设比较合理?
其实只看结构不够,很多模型在内容深度上差距大,单纯四维度可能会忽略细节,尤其是逻辑连贯性和事实准确性,这些才是真正决定可用性的关键。🤔
我之前做过一次评测,发现同题不同模型的表现波动真的很大,三轮才靠谱。
看到有人把‘不要用比喻’忘了,直接跑出一堆比喻,笑死。
模板字数要求太死板,实际写起来经常超。
那如果想评测多语言能力,是不是需要再加个语言覆盖维度?