
文章目录[隐藏]
- 防幻觉清单:10 个信号判断这段话不可信
- 幻觉的 3 种类型(捏造、混淆、过度概括)
- 10 个高危信号:一眼识别不可信内容
- 🚨 信号 1:看起来很具体,但没有来源(危险指数:⭐⭐⭐⭐⭐)
- 🚨 信号 2:时间+事件的组合(危险指数:⭐⭐⭐⭐⭐)
- 🚨 信号 3:引用论文但不给 DOI 或链接(危险指数:⭐⭐⭐⭐⭐)
- 🚨 信号 4:使用"最新研究""有研究表明"等模糊词(危险指数:⭐⭐⭐⭐)
- 🚨 信号 5:数据过于精确(如 47.3%、238 万)(危险指数:⭐⭐⭐⭐)
- 🚨 信号 6:引用"内部报告"“未公开数据”(危险指数:⭐⭐⭐⭐)
- 🚨 信号 7:人名 + 职位 + 观点的组合(危险指数:⭐⭐⭐⭐)
- 🚨 信号 8:统计数据没有样本量和时间范围(危险指数:⭐⭐⭐)
- 🚨 信号 9:用"众所周知""显而易见"做论据(危险指数:⭐⭐⭐)
- 🚨 信号 10:因果关系过于简单(危险指数:⭐⭐⭐)
- 快速核验流程(5 分钟版)
- 核验优先级:先查什么后查什么
- FAQ:如何在不联网情况下自检
- 可打印防幻觉清单(保存收藏)
- 总结:防幻觉的 3 个核心原则
防幻觉清单:10 个信号判断这段话不可信
你让 AI 写了一篇文章,数据详实、引用规范,看起来完全可信。但仔细一查——那篇《自然》杂志论文根本不存在,那个"哈佛大学 2024 年研究"是编造的,那个"增长 300%"的数据来源无处可寻。
这就是 AI 幻觉的可怕之处:看起来越具体,越容易让人放松警惕。
这篇文章给你一份可打印的防幻觉清单,10 个高危信号 + 5 分钟快速核验流程,让你在发布前快速识别哪些内容不可信。

幻觉的 3 种类型(捏造、混淆、过度概括)
AI 幻觉不是随机乱编,而是有规律可循。理解这三种类型,你就能更快识别问题。
类型 1:捏造(Fabrication)
特征:完全不存在的信息,但描述得很具体。
典型案例:
❌ 幻觉输出:
“根据 2024 年《科学》杂志发表的《人工智能对创造力影响的元分析》(作者:张伟、李娜),使用 AI 工具的设计师创造力提升了 47%。”
为什么危险:
- 期刊名真实(《科学》确实存在)
- 论文标题看起来专业
- 作者名字很普通(张伟、李娜)
- 数据具体(47%)
真相:这篇论文不存在,作者是编的,数据是凭空捏造的。
类型 2:混淆(Conflation)
特征:把多个真实信息拼接在一起,形成错误结论。
典型案例:
❌ 幻觉输出:
“OpenAI 的 CEO Sam Altman 在 2024 年 3 月的 TED 演讲中表示,GPT-5 将在年底发布,并且会拥有自主学习能力。”
拆解真相:
- ✅ Sam Altman 是 OpenAI CEO(真)
- ✅ 他确实参加过 TED 演讲(真)
- ❌ 但他从未在 2024 年 3 月的 TED 上说过这些话(假)
- ❌ GPT-5 发布时间和功能是模型推测的(假)
为什么危险:部分信息是真的,让人误以为整段都可信。
类型 3:过度概括(Overgeneralization)
特征:把少量案例或局部现象,夸大成普遍规律。
典型案例:
❌ 幻觉输出:
“研究表明,90% 的自媒体作者使用 AI 工具后,收入提升了 3 倍以上。”
问题:
- “研究表明”——哪个研究?样本量多大?
- “90%”——这个比例从何而来?
- “3 倍”——是平均值还是中位数?是否剔除了极端值?
真相:可能只有一两个小范围调查,甚至是个别成功案例,被模型概括成"普遍规律"。采集失败,请手动处理
10 个高危信号:一眼识别不可信内容
以下是我总结的 10 个最常见的幻觉信号,按危险程度排序。
🚨 信号 1:看起来很具体,但没有来源(危险指数:⭐⭐⭐⭐⭐)
特征:
- 给出了具体的数字、时间、人名、机构
- 但没有标注出处或引用来源
示例:
❌ “2024 年,全球有 230 万人使用 ChatGPT 创业,其中 45% 实现了盈利。”
为什么危险:这是最容易让人中招的幻觉。具体的数字(230 万、45%)让人误以为这是来自权威报告,但实际上可能是模型编造的。
快速判断:如果看到具体数据但没有来源标注,立刻标记为【待核查】。
🚨 信号 2:时间+事件的组合(危险指数:⭐⭐⭐⭐⭐)
特征:
- 给出了具体时间(如"2024 年 3 月")
- 声称在这个时间发生了某事(如"某公司发布报告")
示例:
❌ “2024 年 6 月,麦肯锡发布《AI 对就业影响报告 2.0》,预测 2030 年将有 8 亿人失业。”
为什么危险:
- 麦肯锡确实经常发布报告(真)
- 但这个具体的报告名称和时间可能是编的(假)
快速判断:搜索"机构名 + 报告名 + 时间",看能否找到原文。
🚨 信号 3:引用论文但不给 DOI 或链接(危险指数:⭐⭐⭐⭐⭐)
特征:
- 提到了期刊名(如《Nature》《科学》)
- 给出了论文标题和作者
- 但没有 DOI 编号或论文链接
示例:
❌ “根据《自然》2024 年刊登的《大语言模型认知能力评估》(作者:Smith et al.),GPT-4 的推理能力接近人类平均水平。”
为什么危险:期刊名是真的,但论文可能不存在。
快速判断:
- 去期刊官网搜索论文标题
- 或者搜索"作者名 + 论文标题"
- 如果找不到,99% 是幻觉
🚨 信号 4:使用"最新研究""有研究表明"等模糊词(危险指数:⭐⭐⭐⭐)
特征:
- 声称"有研究"“最新报告”“专家认为”
- 但不说是谁的研究、哪个专家
示例:
❌ “最新研究发现,使用 AI 工具可以让工作效率提升 50%。”
为什么危险:这是模型用来掩盖"我不知道具体来源"的常见话术。
快速判断:看到这类词,立刻追问"哪项研究?谁做的?什么时候发布的?"如果答不上来,就是幻觉。
🚨 信号 5:数据过于精确(如 47.3%、238 万)(危险指数:⭐⭐⭐⭐)
特征:
- 给出了非常精确的数字(保留小数点)
- 或者看起来很"刚好"的整数(如 200 万、50%)
示例:
❌ “2024 年,中国有 238.7 万人使用 AI 工具创业。”
为什么危险:真实的统计数据通常会标注"约"“大约”,或者给出数据范围(如"200-250 万")。过于精确的数字,反而可能是编造的。
快速判断:搜索这个具体数字,看有没有权威来源。
🚨 信号 6:引用"内部报告"“未公开数据”(危险指数:⭐⭐⭐⭐)
特征:
- 声称数据来自"内部报告"“行业白皮书”
- 但这些资料"未公开"或"需要付费获取"
示例:
❌ “根据 OpenAI 内部报告,GPT-5 的训练成本超过 10 亿美元。”
为什么危险:用"内部"“未公开"来掩盖"我编的”。
快速判断:如果无法获取原始报告,标注【无法核验】,并在文中说明"该数据未经公开验证"。
🚨 信号 7:人名 + 职位 + 观点的组合(危险指数:⭐⭐⭐⭐)
特征:
- 给出了具体人名和职位
- 引用了这个人的观点或言论
示例:
❌ “斯坦福大学 AI 实验室主任李华表示,‘AI 将在 2030 年实现通用智能。’”
为什么危险:
- 斯坦福确实有 AI 实验室(真)
- 但"李华"这个主任可能不存在(假)
- 这段话也可能是编的(假)
快速判断:
- 搜索"机构 + 人名",看这个人是否存在
- 搜索"人名 + 引号内的话",看是否有原始出处
🚨 信号 8:统计数据没有样本量和时间范围(危险指数:⭐⭐⭐)
特征:
- 给出了百分比或比例
- 但没有说明样本量、调查时间、调查范围
示例:
❌ “调查显示,75% 的设计师认为 AI 工具提高了工作效率。”
为什么危险:
- 样本量可能只有 10 人(不具代表性)
- 调查时间可能是 5 年前(过时了)
- 调查范围可能只是某个小圈子(不能推广)
快速判断:追问"哪个机构调查的?样本量多大?什么时候的数据?"
🚨 信号 9:用"众所周知""显而易见"做论据(危险指数:⭐⭐⭐)
特征:
- 用"大家都知道"“不言而喻”"毋庸置疑"这类词
- 来回避给出具体证据
示例:
❌ “众所周知,AI 会取代大部分重复性工作。”
为什么危险:这是模型用来掩盖"我没有证据"的话术。
快速判断:看到这类词,立刻删掉,改成"有研究/数据表明……"并要求给出来源。
🚨 信号 10:因果关系过于简单(危险指数:⭐⭐⭐)
特征:
- 声称"A 导致了 B"
- 但没有考虑其他因素
示例:
❌ “使用 AI 工具后,公司收入增长了 50%,可见 AI 是增长的主要原因。”
为什么危险:收入增长可能是因为市场扩大、产品改进、团队扩张等多种因素,不一定是 AI 导致的。
快速判断:看到简单因果关系时,追问"还有没有其他因素?如何排除其他变量?"

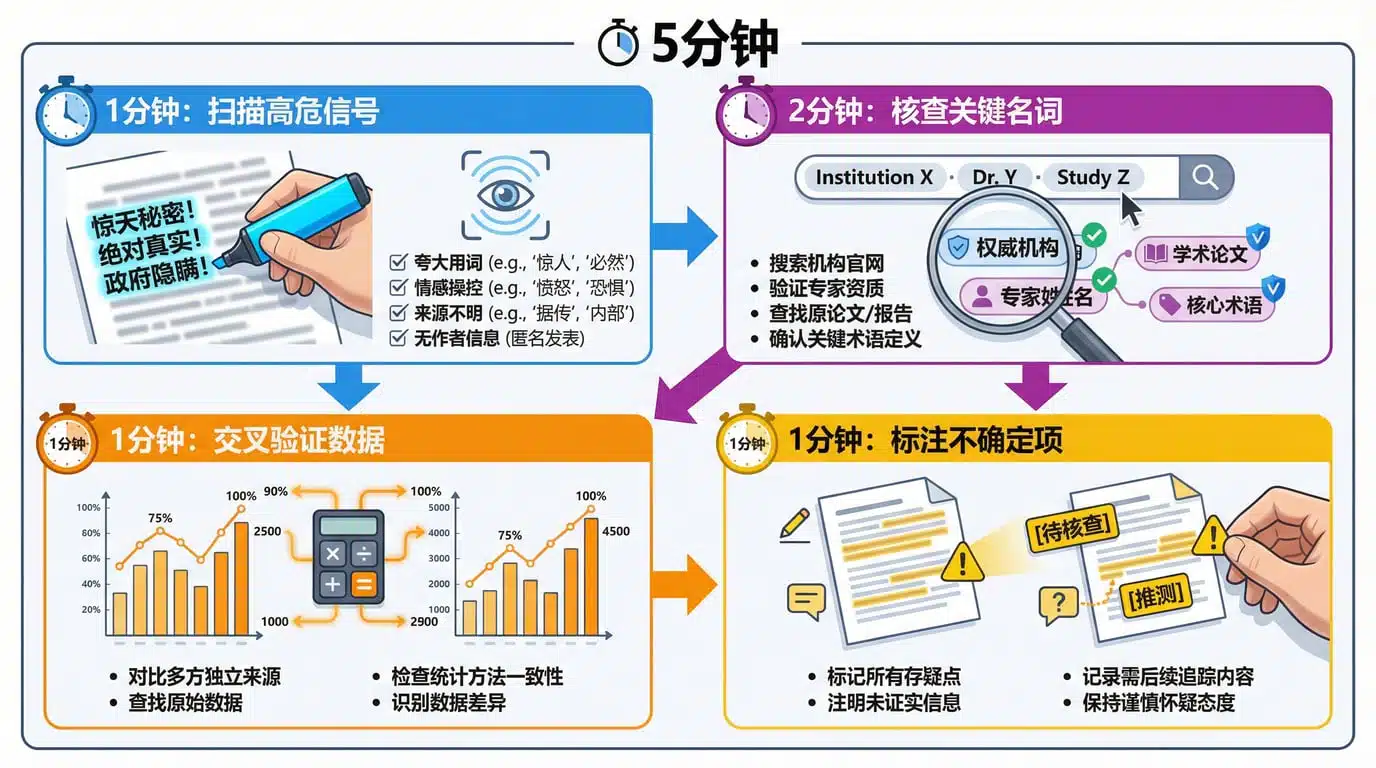
快速核验流程(5 分钟版)
拿到一篇 AI 生成的内容后,按照这个流程快速检查:
⏱️ 1 分钟:扫描高危信号
快速浏览全文,用荧光笔标记:
- ✅ 所有具体数字(如 47%、200 万)
- ✅ 所有时间+事件的组合(如"2024 年 3 月发布报告")
- ✅ 所有人名、机构名、论文标题
- ✅ 所有"研究表明""众所周知"这类模糊词
⏱️ 2 分钟:核查关键名词
选 3-5 个最关键的名词(优先级见下一节),逐一搜索:
- 复制"机构名 + 报告名",看能否找到原文
- 复制"人名 + 职位",看这个人是否存在
- 复制"论文标题 + 期刊名",看能否找到 DOI
⏱️ 1 分钟:交叉验证数据
如果文中有多个数据,看它们是否自洽:
- 比如提到"全球 200 万用户,中国占 50%",那中国应该是 100 万,而不是 150 万
- 比如提到"2023 年增长 50%,2024 年增长 30%",那总增长应该是 95%(1.5×1.3-1),而不是 80%
⏱️ 1 分钟:标注不确定项
对于无法快速验证的内容,加上标注:
【待核查】:看起来可疑,但暂时没时间查【推测】:这是基于部分信息的推测,不是确凿事实【存在争议】:这个说法有不同观点
核验优先级:先查什么后查什么
如果时间有限,按照这个优先级核查:
🔴 优先级 1:时间相关(最容易核查,也最容易暴露幻觉)
为什么优先:
- 时间信息最容易验证(搜索"事件 + 时间"即可)
- 一旦时间错了,整段内容可信度立刻归零
核查方法:
- 复制"时间 + 事件"(如"2024 年 3 月 OpenAI 发布 GPT-5")
- 搜索看有无新闻报道或官方公告
- 如果找不到,立刻标记【时间错误】
🟠 优先级 2:专有名词(机构、人名、产品名)
为什么次之:
- 名词错误通常意味着整个引用是编造的
- 验证成本适中(搜索即可)
核查方法:
- 复制"机构名 + 关键词"(如"麦肯锡 + AI 报告")
- 去官网或权威数据库搜索
- 如果找不到,标记【来源可疑】
🟡 优先级 3:具体数据(百分比、数量)
为什么第三:
- 数据核查成本较高(需要找到原始报告)
- 但数据错误影响可信度
核查方法:
- 搜索"数据 + 来源机构"(如"47% + 麦肯锡")
- 看能否找到原始报告的图表或摘要
- 如果只能找到二手转述,标记【待核查】
🟢 优先级 4:观点和结论
为什么最后:
- 观点本身可以有争议,不一定是"对"或"错"
- 重点是观点是否有证据支持
核查方法:
- 看这个观点前面是否有证据
- 证据是否可靠(见优先级 1-3)
- 如果没有证据,标记【缺乏支持】
FAQ:如何在不联网情况下自检
如果你在没有网络的情况下需要初步判断内容可信度,可以用这些方法:
方法 1:逻辑自洽检查
问自己 3 个问题:
- 文中的数据是否自相矛盾?
- 时间线是否合理?(比如提到"2024 年发布的报告引用了 2025 年的数据")
- 因果关系是否过于简单?
示例:
❌ “2024 年,全球 AI 市场规模达到 5000 亿美元,其中中国占 80%,美国占 30%。”
→ 问题:80% + 30% = 110%,数据自相矛盾。
方法 2:常识判断法
用常识判断以下情况:
- 这个数据是否过于夸张?(如"使用 AI 后收入增长 1000%")
- 这个时间是否过于巧合?(如"刚好在 2024 年 1 月 1 日发布")
- 这个人名是否过于普通?(如"张伟""李娜"这种大众名字,反而可能是编的)
方法 3:来源类型检查
看文中是否标注了来源类型:
- ✅ 好的标注:
[学术研究]、[政府数据]、[企业公告] - ❌ 危险标注:
[最新研究]、[有专家认为]、[众所周知]
如果通篇都是模糊来源,可信度大打折扣。
方法 4:重新生成对比法
具体操作:
- 把同样的提示词,让 AI 再生成一遍
- 对比两次输出中的具体数据(如时间、人名、数字)
- 如果两次输出的数据完全不同,说明这些数据是编造的
示例:
- 第一次输出:“2024 年,全球有 200 万人使用 ChatGPT 创业。”
- 第二次输出:“2024 年,全球有 350 万人使用 ChatGPT 创业。”
→ 结论:这个数字是模型随机生成的,不可信。
可打印防幻觉清单(保存收藏)
以下是一份可打印的核查清单,建议打印后贴在电脑旁边,每次发布内容前快速过一遍:
┌─────────────────────────────────────────────┐
│ 防幻觉核查清单(发布前必查) │
└─────────────────────────────────────────────┘
□ 第 1 步:扫描高危信号(1 分钟)
□ 是否有具体数字但没标注来源?
□ 是否有"时间+事件"的组合?
□ 是否有论文引用但没有 DOI?
□ 是否有"最新研究""有专家认为"这类模糊词?
□ 是否有过于精确的数据(如 47.3%)?
□ 第 2 步:核查关键名词(2 分钟)
□ 机构名是否真实存在?
□ 人名 + 职位是否匹配?
□ 论文标题能否搜到原文?
□ 报告名称能否在官网找到?
□ 第 3 步:交叉验证数据(1 分钟)
□ 文中多个数据是否自洽?
□ 百分比相加是否超过 100%?
□ 时间线是否合理?
□ 第 4 步:标注不确定项(1 分钟)
□ 无法验证的内容是否标注【待核查】?
□ 推测性内容是否标注【推测】?
□ 有争议的观点是否标注【存在争议】?
□ 第 5 步:最终确认
□ 文末是否附上"待核查清单"?
□ 是否提醒读者"部分数据需进一步验证"?
□ 关键数据是否保留了验证痕迹(如来源链接)?
┌─────────────────────────────────────────────┐
│ ⚠️ 核查优先级提醒 │
│ 1️⃣ 时间相关(最容易查,最容易暴露幻觉) │
│ 2️⃣ 专有名词(机构、人名、产品) │
│ 3️⃣ 具体数据(百分比、数量) │
│ 4️⃣ 观点结论(看是否有证据支持) │
└─────────────────────────────────────────────┘
┌─────────────────────────────────────────────┐
│ 🔴 危险信号速查表 │
│ • 看起来很具体但没来源 → 最危险! │
│ • "最新研究""有专家认为" → 模糊来源 │
│ • 数据过于精确(47.3%)→ 可能编造 │
│ • "众所周知""显而易见" → 回避证据 │
│ • 简单因果关系 → 忽略其他变量 │
└─────────────────────────────────────────────┘

总结:防幻觉的 3 个核心原则
- 具体但没来源 = 最危险:越是看起来"有鼻子有眼"的描述,越要警惕。模型最擅长编造"看起来像真的"的细节。
- 优先核查时间和名词:这两项最容易验证,也最容易暴露幻觉。如果时间错了或人名是编的,整段内容可信度归零。
- 标注不确定性反而更可信:主动承认"这个数据待核查"“这是推测”,读者反而会更信任你的内容。
立即行动
- 打印这份清单,贴在电脑旁边
- 选一篇 AI 生成的内容,用 5 分钟流程跑一遍
- 建立自己的"待核查清单",每次发布前过一遍
记住:你的可信度 = 你发布内容的最低质量。一次幻觉内容被发现,之前建立的信任就会崩塌。花 5 分钟核查,能避免 99% 的信任危机。
如果你已经在用这份清单,欢迎在评论区分享你发现的"高危幻觉案例"——我们可以一起完善这套防幻觉系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



评论已关闭...
这清单真的帮大忙,太实用了。
感觉还行,值得一试。
顺带一提,我用Excel写了个模板,快速对照数字更省事。
这个“最新研究”到底是哪家机构的?
我看这数字太精准了,估计是造的。
之前我也被类似的AI报告坑了好几天。
这类标题党真让人翻白眼。
哈哈,看到有人直接转贴,笑死。
我在群里看到这篇,大家在聊这份清单的可信度如何?你们有核查过吗
如果把这套核查流程套到公司内部报告,会不会把所有部门的自夸都挑出来?🤔真的会不会很尴尬呢?
这清单第3条太真实了,上次看到个“Nature论文”死活搜不到😂
我拿它核了篇AI写的行业分析,光信号1就中了5处!
“内部报告”四个字一出来我就直接不信了
有人试过用这流程查自媒体吹的AI收入数据吗?
之前搞过AI内容审核,确实捏造类最难防
47.3%这种数看着就假,谁统计能精确到小数点后一位啊
要是连时间都对不上还发出来,编辑是睡着了吗?
这方法能套进我们周报里吗?老板最爱编“据调研”了🤔