Jeff Dean 斯坦福演讲深度回顾:AI 激荡十五年与 Gemini 的多模态未来
如果我们要为过去 15 年的计算机科学找一个代名词,那一定是“深度学习”。
最近,Google DeepMind 的首席科学家 Jeff Dean 受邀来到斯坦福 AI 俱乐部(SVSAI),发表了一场题为 The Exciting Path of AI: Past, Present, and Future 的演讲。作为 MapReduce、BigTable、Spanner 以及 TensorFlow 的缔造者之一,Jeff Dean 不仅是 Google 基础架构的灵魂人物,更是 AI 规模化时代的见证者。
在这场演讲中,他并没有仅仅停留在对 Google 最新模型 Gemini 的宣传上,而是抽丝剥茧,回顾了从 2010 年代初期的 DistBelief 系统到如今万亿参数大模型的技术演进路线。
为什么我们能在短短十几年间,从勉强识别一只猫,进化到能解奥数题?
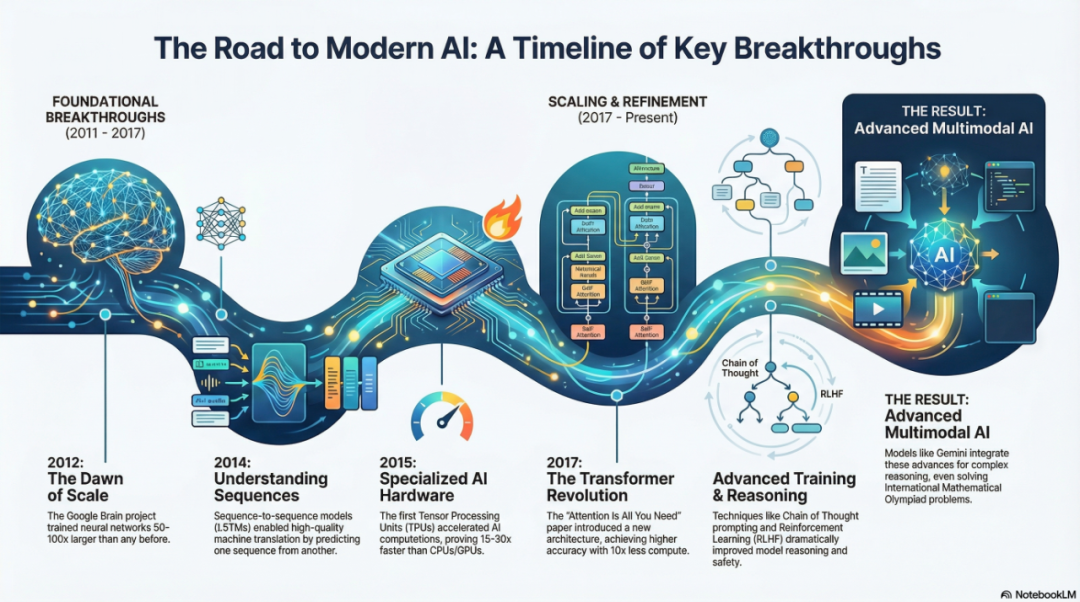
第一阶段:规模化的觉醒 (2011-2015)
1. 从“手动规则”到“数据驱动”
Jeff Dean 开篇点出了 AI 范式的根本转变。在 2010 年之前,计算机视觉和自然语言处理(NLP)主要依赖人工编写的特征和规则。那时候,要在图片中找到一只猫,需要工程师定义“耳朵是尖的”、“有胡须”等规则。
而深度学习改变了一切:我们不再告诉计算机怎么做,而是给它足够的数据,让它自己学。
2. DistBelief 与“猫的论文” (The Cat Paper)
演讲中提到了一个里程碑式的时刻——2012 年著名的“猫脸识别实验”。
当时,Google 团队利用 DistBelief(TensorFlow 的前身)构建了一个包含 10 亿参数的神经网络,并在 1.6 万个 CPU 核心上运行。他们给模型“看”了 1000 万帧从 YouTube 随机抽取的视频画面,没有给任何标签。
结果令人震惊:网络中的某个神经元自动学会了识别“猫”。这证明了无监督学习(Unsupervised Learning)结合大规模计算,可以自发涌现出高层概念。
3. 语言的向量化:Word Embeddings
与此同时,NLP 领域也在发生巨变。Jeff 回顾了 Word Embeddings(词嵌入) 的诞生。通过将单词映射到高维向量空间,计算机第一次“理解”了词与词之间的关系。
那个经典的公式至今仍让人津津乐道:
King - Man + Woman = Queen
这意味着模型不仅记住了单词,还捕获了性别、地位等语义维度。
第二阶段:架构与硬件的共舞 (2015-2018)
4. 算力的瓶颈与 TPU 的诞生
随着模型越来越大,通用的 CPU 开始力不从心。Google 发现,神经网络的计算并不需要传统 CPU 那么高的精度(64位或32位浮点数),低精度的线性代数运算才是关键。
于是,TPU (Tensor Processing Unit) 应运而生。Jeff 展示的数据显示,初代 TPU 在 AI 负载下的效率比当时的 CPU/GPU 高出 15-30 倍,能效比更是高出 30-80 倍。这就是为什么 Google 能够比竞争对手更早地将 AI 部署到搜索和翻译等大规模产品中。
5. Transformer:注意力就是一切
如果说 TPU 是引擎,那么 Transformer 就是那个改变游戏规则的引擎图纸。
在 2017 年之前,LSTM(长短期记忆网络)是处理序列数据的主流。但 LSTM 必须按顺序阅读(从左到右),难以并行训练。
Attention Is All You Need 论文的发表彻底改变了这一局面。Self-Attention(自注意力机制) 允许模型同时关注句子中的所有单词,无论距离多远。这不仅极大地提升了翻译质量,更重要的是,它释放了并行计算的潜力,为后来 GPT 和 BERT 等大模型的爆发奠定了基础。
第三阶段:通往高效与推理 (2019-Present)
6. 稀疏模型 (Sparse Models):大而不臃肿
这是演讲中非常硬核的一个技术点。随着模型参数迈向万亿级别,每次推理都激活所有参数变得极其昂贵。
Jeff 重点介绍了 Mixture of Experts (MoE) 等稀疏模型架构。其核心理念是:就像人脑一样,处理数学题时不需要激活负责跳舞的脑区。
通过稀疏激活,模型可以在保持极大规模(拥有广博知识)的同时,每次推理只使用 1-5% 的参数(保持低延迟和低成本)。
7. 思维链 (Chain of Thought) 与推理
大模型不再只是“概率鹦鹉”。通过 Chain of Thought (CoT) 提示,模型学会了在给出答案前先生成推理步骤。Jeff 展示了模型如何通过一步步的逻辑推导,解决了以前无法处理的复杂数学应用题。
第四阶段:Gemini 与未来展望
演讲的最后部分,Jeff Dean 演示了 Google 最新的 Gemini 系列模型,特别是其原生多模态能力。
-
全能感知:Gemini 不再是挂载了“眼睛”的文本模型,它是原生训练的,能同时理解文本、图像、视频和音频。 -
数学奥林匹克:Jeff 自豪地展示了 AI 在国际数学奥林匹克(IMO)级别的解题能力,这意味着 AI 的逻辑推理能力已经达到了人类顶尖水平。 -
代码生成:从草图到可运行的网站,AI 正在重塑软件工程的流程。
Jeff Dean 在演讲结束时提到,AI 正在成为科学发现的加速器(如 AlphaFold 对生物学的贡献)。尽管存在幻觉(Hallucination)和虚假信息等挑战,但他对未来保持乐观。
回顾 Jeff Dean 的这次演讲,最让人感触的不是某个具体的模型,而是技术演进的必然性。从算力的堆叠,到架构的精简,再到对“推理”本质的追求,AI 的进化史就是一部人类试图复刻并超越自身认知的历史。
下一个 15 年,当我们回顾今天时,Gemini 哪怕是 3.0 版本,可能也会像当年的“猫脸识别”一样,显得既原始又充满开创性。
<
Jeff Dean真是AI领域的传奇人物,每次演讲都让人收获满满!
从猫脸识别到Gemini,这十五年发展速度太惊人了!
TPU那段讲得好,硬件突破确实是AI普及的关键。
有人能解释一下稀疏模型吗?听起来很厉害但不太懂原理🤔
Gemini的多模态能力确实强,但实际应用还有多远?
对比OpenAI,Google在推理方面的进展似乎更扎实。